前言
NetVLAD 确实是计算机视觉中一个里程碑式的工作,它不仅连接了传统特征工程(SIFT, VLAD)与深度学习,更是开启了端到端位置识别(Visual Place Recognition)的时代。
简单来说,NetVLAD 的核心贡献在于将传统的无监督聚类算法(如 K-Means)和特征聚合方法(VLAD)转化为了一个可微的(Differentiable)、可训练的神经网络层,从而允许网络直接针对“位置识别”这一任务进行端到端的优化,而不再依赖手工设计的特征。
为了彻底理解 NetVLAD 的设计动机,我们需要先建立一套统一的数学符号。
基础符号定义:
假设我们需要描述一张图片:
- $X = {x_1, x_2, …, x_N}$:这是一张图像中提取出的 $N$ 个局部特征描述子(例如 SIFT 向量)。每个 $x_i$ 都是 $D$ 维的向量。
- $C = {c_1, c_2, …, c_K}$:这是我们通过 K-Means 算法预先训练好的 $K$ 个聚类中心(也叫“视觉词汇”,Visual Words)。每个 $c_k$ 也是 $D$ 维的
第一阶段:词袋模型 (Bag of Words, BoW) —— “硬分配”与“计数”
BoW的核心思想非常简单:我们只关心特征“掉”进了哪个聚类中心,然后数个数。简而言之可以总结为以下两个步骤:
1. 硬分配 (Hard Assignment):
对于每一个特征 $x_i$,我们通过寻找最近邻,将其分配给唯一的聚类中心 $c_k$。
我们定义一个分配函数 $a_k(x_i)$:
$$ a_k(x_i) = \begin{cases} 1, & \text{如果} k = \operatorname*{argmin}_{j} \|x_i-c_j\|^2 \\ 0, & \text{其他情况} \end{cases} $$2. 聚合 (Aggregation):
BoW 的最终向量只是一个直方图。对于第 $k$ 个聚类中心,它的值就是分配给它的特征数量:
$$ V_{\text{BoW}}[k] = \sum_{i=1}^{N} a_k(x_i) $$这个向量的长度是 $K$。
第二阶段:VLAD —— 从“计数”到“向量和”
VLAD (Vector of Locally Aggregated Descriptors) 引入了残差 (Residual) 的概念。它记录的是每个居民相对于市中心的相对位置
“残差”:
对于赋给中心 $c_k$ 的特征 $x_i$,残差向量为:
$$ x_i - c_k $$在 BoW 中,我们要的是 0阶统计量(计数):
$$ V_{\text{BoW}}[k] = \sum_{i=1}^{N} a_k(x_i) \cdot 1 $$VLAD 想要的是 1阶统计量(残差和)。也就是把所有属于簇 $k$ 的特征的残差向量全部加起来。
$$ V_{\text{VLAD}}[k]= \sum_{i=1}^{N} a_k(x_i) \cdot (x_i - c_k) $$其中,残差向量为 $D$ 维,则最终的VLAD向量为 $K\cdot D$ 维
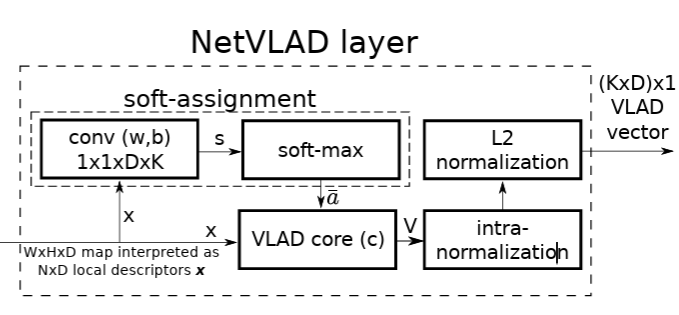
第三阶段:NetVLAD —— 软分配 (Soft Assignment)
现在我们已经有了 VLAD 的数学形式,但如果直接把它放进神经网络里训练,有一个巨大的障碍。请看公式里的 $a_k(x_i)$ 项。在传统 VLAD 中,这是一个硬分配(Hard Assignment):
$$ a_k(x_i) = 1 \text{ (如果是最近邻) 否则 } 0 $$这就意味着这是一个非黑即白的argmax操作。正是因为argmax是不可导的(或者说导数几乎处处为 0),会导致梯度消失(Gradient Vanishing),无法反向传播来更新前面的特征提取网络。
NetVLAD的核心变革:软分配 (Soft Assignment)
为了解决这个问题,NetVLAD 借鉴了 T-SNE 等算法的思想,使用Softmax将“非 0 即 1”的硬分配变成了一个概率分布。
对于第 $k$ 个聚类中心 $c_k$ 和特征 $x_i$,软分配权重 $\bar{a}_k(x_i)$ 定义为:
$$ \bar{a}_k(x_i) = \frac{e^{-\alpha \|x_i - c_k\|^2}}{\sum_{j} e^{-\alpha \|x_i - c_j\|^2}} $$这里的 $\alpha$ 是一个控制参数:
- $\alpha \to \infty$ 时,这就逼近硬分配(One-hot)。
- $\alpha \to 0$ 时,分配趋于平均。
NetVLAD 的精妙之处在于它不仅提出了软分配,还发现可以用标准的 CNN 操作(卷积/全连接)来实现它,从而能无缝嵌入任何网络
$$ -\alpha \|x_i - c_k\|^2 = -\alpha (\|x_i\|^2 - 2c_k^T x_i + \|c_k\|^2) $$在 Softmax 的计算中,$-\alpha |x_i|^2$ 这一项对于分母中所有的 $j$ 都是一样的常数,因此分子分母相除时这一项会被消掉。所以我们只需要关注剩下的部分:
$$ \text{Score}_k = 2\alpha c_k^T x_i - \alpha \|c_k\|^2 $$这个 $\text{Score}_k$ 看作是神经网络中一个标准的线性操作,或者是 $1 \times 1$ 卷积
$$ y = w \cdot x + b $$$\text{Score}$的计算可以理解为神经网络计算出的logits,即对特征$x_i$,神经网络对它分配到聚类$c_k$的打分。此时不难发现:
- Weight ($w_k$): $2\alpha c_k$。这代表聚类中心的方向向量,负责测量输入特征与中心的相似度。
- Bias ($b_k$): $-\alpha |c_k|^2$。这是对聚类中心模长的补偿(模长越大的中心,需要减去越多的能量,以保持公平比较)。
因此利用Conv2d能够并行计算的特性,不用编写任何复杂的自定义 CUDA 核函数来计算距离,我们就能高效计算分配分数了。
上面其实已经给出公式了,要实现软分配,计算出来的logits还需要进行softmax的计算才能转化为概率:
$$ \bar{a}_k(x_i) = \text{Softmax}(Score_i) $$矩阵视角的计算优化
虽然数学公式是 $V_k = \sum \bar{a}_k(x_i) \cdot (x_i - c_k)$,但在实际的深度学习代码(如 PyTorch)中,如果我们真的先去计算每一个像素 $x_i$ 和每一个中心 $c_k$ 的差 $(x_i - c_k)$,会产生一个巨大的张量,导致显存爆炸
比如:对于一个16*16的特征图,聚类数64,特征维度768,那么计算的中间张量大小为:
$$ 16 \times 16 \times 64 \times 768 \times 4 \text{Bytes} = 50,331,648 \text{Bytes} \approx 48\text{MB} $$这还只是一张图的大小…
因此,为了避免显存爆炸,NetVLAD 在实现时利用了一个简单的数学变换(分配律),将公式拆成了两部分分别计算。
利用分配律展开:
$$ V_{\text{VLAD}}[k] = \underbrace{\sum_{i=1}^{N} \bar{a}_k(x_i) x_i}_{\text{第一项}} - \underbrace{\sum_{i=1}^{N} \bar{a}_k(x_i) c_k}_{\text{第二项}} $$注意第二项中,$c_k$ 与求和下标 $i$ 无关,可以提取到求和符号外面:
$$ V_{\text{VLAD}}[k] = \underbrace{\sum_{i=1}^{N} \bar{a}_k(x_i) x_i}_{\text{Term A}} - \underbrace{c_k \left( \sum_{i=1}^{N} \bar{a}_k(x_i) \right)}_{\text{Term B}} $$在代码编写中我们通常叫这两项为“特征加权和”v_x,以及“中心加权和”v_c
对于上述这两项的矩阵计算可以表述如下:
Term A: 特征加权和 (Weighted Sum of Descriptors)
数学操作:矩阵乘法 $A \times X^T$。
- $A$ (Soft Assign): 形状 $(K, N)$。
- $X$ (Descriptors): 形状 $(D, N)$。
运算结果:$(K, N) \times (N, D) \rightarrow (K, D)$。
计算量 (FLOPs):仍然保持在$O(NKD)$量级,但不需要存储$N \times K \times D$ 的中间量
Term B: 中心加权和 (Weighted Sum of Centers)
- 数学操作:先求和,再广播乘法。
- 对 $A$ 在 $N$ 维度求和(Sum):$S = \sum A$。形状 $(K, N) \rightarrow (K, 1)$。计算量 $N \cdot K$。
- 与中心 $C$ 乘法:$S \cdot C$。形状 $(K, 1) \times (K, D)$(广播乘法)。计算量 $K \cdot D$。
- 总计算量:$N \cdot K + K \cdot D$。
- 对比:Term B 的计算量远小于 Term A,几乎可以忽略不计。
总空间复杂度大幅降低,不再需要去存储巨大的$(N, K, N)$张量
NetVLAD核心三件套
Input-Normalization、Cluster init、Intra-Normalization
首先说为什么要Input norm?
从“理论角度”出发可以这样解释:
NetVLAD 的核心是基于欧氏距离来计算软分配(Soft Assignment)的:
$$ d(x, c) = \|x - c\|^2 = \|x\|^2 - 2c^T x + \|c\|^2 $$而归一化的作用在于我们可以将“常数项”:$|x|^2$ (也是输入特征的模长)变为常数1,使得整个特征分布在单位超球面上,欧氏距离完全等价于余弦相似度(点积)。我们希望这样分配的完全由方向相似度($\cos \theta$)决定,不受受特征向量模长(Magnitude)的影响。比如:假设图像中有一块“阴影区域”(特征值整体很小,$|x| \approx 0.1$)和一块“高光区域”(特征值很大,$|x| \approx 10$)。
- 对于高光区域,$|x|^2$ 这一项高达 100,它会主导整个距离公式。
- 此时,$c^T x$(方向相似度)的权重被淹没。
在实际“代码实现”的情况下:
我们之前的推导中用 $1 \times 1$ 卷积 $w_k \cdot x_i$(即 $2\alpha c_k^T x_i$)来模拟距离,而不是真正在实现$-|x_i - c_k|^2$。 因此,此时Input-Normalization的作用在于——控制打分尺度,Softmax 饱和、减少异常 token 造成的簇主导,从而改善训练稳定性和簇覆盖。
在实际使用NetVLAD的时候,不必完全追寻其VLAD的理论范式(这里涉及NetVLAD的 $w、b、c$ 解耦问题)。当输入特征使用了LN或者白化的时候通常也不太需要进行Input L2-norm,首先对于LN
$$ LN(x) = \frac{x - \mu}{\sigma} \cdot \gamma + \beta $$其中 $\mu$ 是均值,$\sigma$ 是标准差。对于一个 $D$ 维向量 $x \in \mathbb{R}^D$,经过 LayerNorm 后,它的每一个元素 $x_i$ 近似满足标准正态分布(或者至少是均值 0 方差 1 的分布)。因为 $x_i$ 的方差被归一化为 1(即 $E[x_i^2] \approx 1$),根据大数定律,当 $D$ 很大时:
$$ \|x_{\text{LN}}\|^2 = \sum_{i=1}^{D} x_i^2\approx D $$上述只是最理想的情况,实际上LN里的两个参数$\gamma、\beta$是可学习的,如果网络发现某些 Token 需要更强的表达力,它会学习出更大的 $\gamma$,导致这些 Token 的模长显著大于 $\sqrt{D}$。但无论如何,LN之后的特征幅值依然被限制在一定的超椭球特征空间里,依然有利于稳定的Softmax计算。而白化比 LayerNorm 更进一步:
$$ x_{\text{white}} = \Sigma^{-\frac{1}{2}}(x - \mu) $$不仅让特征均值为 0、方差为 1,还去除了特征之间的相关性(把协方差矩阵变成单位矩阵 $I$)
然后是NetVLAD的初始化方式
以下是融合了 Nanne 的 Data-driven Alpha 和 数学正确的 Bias 的最佳初始化代码:
def init_params(self, clsts, descs):
import faiss
# 1. 计算 Alpha (基于数据密度)
index = faiss.IndexFlatL2(clsts.shape[1])
index.add(descs)
# 找每个聚类中心最近的2个训练点
D, _ = index.search(clsts, 2)
# D 已经是距离平方
self.alpha = -np.log(0.01) / np.mean(D[:,1] - D[:,0])
self.alpha = min(self.alpha, 100.0) # Safety Clamp
with torch.no_grad():
self.centers.copy_(torch.from_numpy(clsts).to(device=device, dtype=dtype))
# 2. 初始化权重 (Convolution Weights)
# w = 2 * alpha * c
self.assign.weight.data.copy_(
(2.0 * self.alpha * torch.from_numpy(clsts)).unsqueeze(-1).unsqueeze(-1)
)
# 3. 初始化偏置 (Convolution Bias)
# bias = - alpha * ||c||^2
sq_norm = np.sum(clsts**2, axis=1)
self.assign.bias.data.copy_(
- self.alpha * torch.from_numpy(sq_norm)
)
最后是Intra-normalization
是 VLAD 和 NetVLAD 中最“反直觉”但最重要的步骤。
问题背景:Visual Burstiness(视觉爆发) 在图像检索中,我们经常遇到这种现象:一张图片里包含了一棵树,树上有 1000 片叶子。
- 这 1000 片叶子的局部特征 $x_i$ 几乎一模一样。
- 它们都会被分配到同一个聚类中心(比如“植被簇”)。
- 在计算 Sum Residuals 时,这 1000 个向量叠加,会导致该簇的残差向量 $V_k$ 模长巨大。
而图片里还有一个关键的特征:路牌(可能只有 10 个像素点)。
- 路牌被分配到“标志簇”,叠加后模长很小。
后果:
如果不做处理,最终的 $K \times D$ 向量拼接后,“树叶簇”的能量将完全掩盖“路牌簇”的能量。当我们计算两张图片的相似度(点积)时,比的完全是谁的树叶多,而不是谁有路牌。
Intra-normalization 的数学推导:
为了解决这个问题,我们在拼接之前,先对每一个簇的残差向量 $V_k$ 单独做 L2 归一化:
$$ V_k \leftarrow \frac{V_k}{\|V_k\|_2 + \epsilon} $$假设 $K=2$(只有两个簇:树叶、路牌),特征维度 $D=2$(简化)。
- 场景 1:图片 A(很多树叶,有一个路牌)
- 簇 1(树叶)聚合结果:$[100, 100]$ (模长 $\approx 141$)
- 簇 2(路牌)聚合结果:$[1, 2]$ (模长 $\approx 2.23$)
- 不做 Intra-norm:拼接向量 $[100, 100, 1, 2]$。归一化后,路牌信息几乎为 0。
- 做 Intra-norm:
- 簇 1 归一化 $\to [0.707, 0.707]$
- 簇 2 归一化 $\to [0.447, 0.894]$
- 拼接向量:$[0.707, 0.707, 0.447, 0.894]$。
- 结果:树叶和路牌在描述子中占据了同等的权重。
- 意义总结:Intra-normalization 强制让每一个被激活的聚类中心,无论它包含了多少个重复的特征点,其贡献度都被限制在单位圆上。它抑制了重复纹理(Burstiness),提升了稀有特征(如有辨识度的地标建筑)的权重。
NetVLAD完整代码
class NetVLAD(nn.module):
def __init__(
self,
in_channels: int,
num_clusters: int = 64,
normalize_input: bool = True,
):
self.in_channels = in_channels
self.num_clusters = num_clusters
self.normalize_input = normalize_input
self.assign = nn.Conv2d(in_channels, num_clusters, kernel_size = 1, bias = True)
self.centers = nn.Parameter(torch.rand(num_clusters, in_channels))
self.clst = None
self.desc = None
def init_from_clusters(clst, desc):
import faiss
"""
与上文保持一样
"""
def forward(self, x: torch.Tensor):
"""
Forward pass
Args:
x (torch.Tensor): Input tensor of shape [B,C,H,W]
Return:
v (torch.Tensor): VLAD global tensor
"""
if self.normalize_input:
x = F.normalize(x, p=2, dim=1)
logits = self.assign(x)
a = F.softmax(logits, dim=1) # [B, K, H, W]
a_flat = a.flatten(2) # [B, K, N]
x_flat = x.flatten(2) # [B, C, N]
v_x = torch.bmm(a_flat, x_flat.transpose(1,2)) # [B, K, C]
a_sum = torch.sum(a_flat, dim=-1) # [B, K]
v_c = self.center.unsqueeze(0) * a_sum.unsqueeze(2) # [B, K, C] = [1, K, C] * [B, K, 1]
v = v_x - v_c # [B, K, C]
# intra-normalization
v = F.normalize(v, p=2, dim=-1)
v = v.flatten(1)
v = F.normalize(v, p=2, dim=-1)
return v
评论